
Ruszyło mnie do napisania tego postu, bo pewnie ktoś może mieć podobne przygody. Otóż w ostatnim dniu przedłużonego terminu zgłosiłem się do Dziekanatu mojej uczelni (tak, po czterdziestce też się da), by złożyć moją wypieszczoną pracę dyplomową. Regulamin powiadał o konieczności złożenia pracy w formacie .doc i .pdf, ale ja postawiłem na to, że to odpowiedni moment na to by zrobić coś poważnego w LaTeX’u. Ładnych kilka(naście) lat zajmowałem się składem tekstu, poskładałem ileśtam książek, czy innych druków. Od samego początku typografia była moim konikiem. I jak tutaj teraz miałbym składać w Wordzie? Na szczęście mój Promotor nie widział problemów. W końcu LaTeX to uczelniany najwyższy standard od lat w wielu uczelniach na świecie.
I było pięknie do momentu, aż Pani w Dziekanacie (pozdrawiam za cierpliwość) w moim wypieszczonym PDF-ie zrobiła ctrl+a, ctrl+c, by potem wkleić tekst w systemie antyplagiatowym. I niestety. Zamiast polskich znaków jakieś krzaki. I diagnoza: — Nie mogę panu przyjąć tej pracy.
Nieźle. Ostatni dzień. Zacząłem intensywnie myśleć co jest nie tak. Dziekanat jeszcze pół godziny czynny. Co jest grane. Pracę składałem w texmakerze na Mac’u. Moje podejrzenia od razu skierowały się na unikod i jakiś ból w systemie antyplagiatowym. U mnie kopiowanie z świeżo wyprodukowanego PDF-a i wklejanie do edytora tekstowego nie pokazuje niczego złego:


Lecz niestety okazało się, że po zmianie maszyny, otwarciu na innym komputerze w przeglądarce Adobe w skopiowanym tekście znajdujemy inne znaki niż miały być.

I co teraz? Unikod odpada. Pierwsze kroki skierowałem w źródła TeX’owe. Porównywałem stworzone z tego samego zestawu nagłówków dokumenty. Praca vs. Referat. I tutaj zauważyłem, że kopiowany tekst z Referatu nie wykazuje błędnego kodowania polskich znaków. Co jest grane? Prawdopodobnie w Referacie nie używam jakiegoś pakietu, który pomimo wyliczenia go w TeX’owych nagłówkach nie bierze udziału w kompilacji. Moje nagłówki Referatu:
\documentclass[12pt,a4paper,oneside,polish]{dcsbook}
\usepackage[utf8]{inputenc}
\usepackage[polish]{babel}
\usepackage{hyperref}
\usepackage{listings}
\usepackage{color}
Nie przedłużając. Dopisanie:
\usepackage{cmap}
sprawiło, że uzyskałem coś, co powinno zaspokoić potrzeby uczelnianego systemu antyplagiatowego (mam nadzieję). Cmap to pakiet bazujący na tablicy znaków firmy Adobe. Czyli twórcy formatu PDF. Powinno być lepiej. I chyba jest, bo w windowsowym Adobe Readerze robię kopiuj:
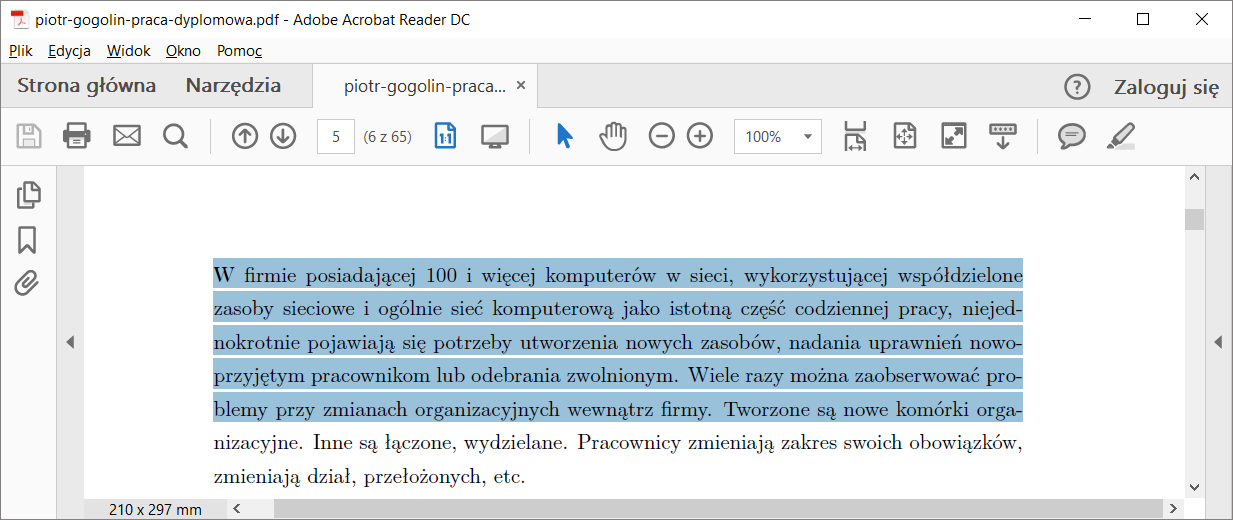
I sytuacja w windowsowym kopiowaniu:
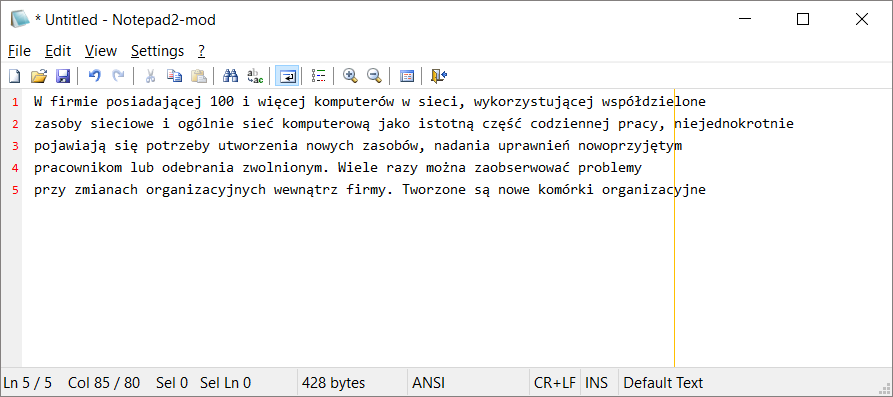
Powyższy wklejony test jest w windowsowym kodowaniu (ANSI). Mam nadzieję, że tyle wystarczy, by pracę zarejestrować w systemie antyplagiatowym. [edit: wystarczyło]
Sam PDF ma warstwę wizualną i warstwę, która kryje się pod wyrysowanymi czcionkami. Jak widać na poniższym przykładzie zaznaczenie tekstu pozwoli skopiować niewidoczne dla nas warstwy tekstowe. Cały ambaras w tym, aby było tam to, co widać na warstwie graficznej. Cmap wydaje się rozwiązywać problem.
Ciesze się, że trafiłem na Twoją stronę. Miałem podobny problem, może nie aż tak krytyczny jak oddanie pracy dyplomowej ale nie działało kopiowanie ze względu na krzaki. Teraz działa! Dzięki.
Zapewne się obroniłeś, gratuluję.
Dzięki. Cieszę się że pomogłem. Obrona wyszła perfekt.